UX Research
in the age of the reproducibility crisis
Our story starts with
TED
ted.com/talks/amy_cuddy_your_body_language_shapes_who_you_are
Field study
High power poses
Low power poses
Reproducibility project
Just wait til you see their results
"97% of the original results showed a statistically significant effect, this was reproduced in only 36% of the replication attempts"
"...the idea became a shorthand for flashy social psychological work that could not be replicated..."
What's to blame?
- "Publish or perish"
- No replication studies
- Clickbait
P-hacking
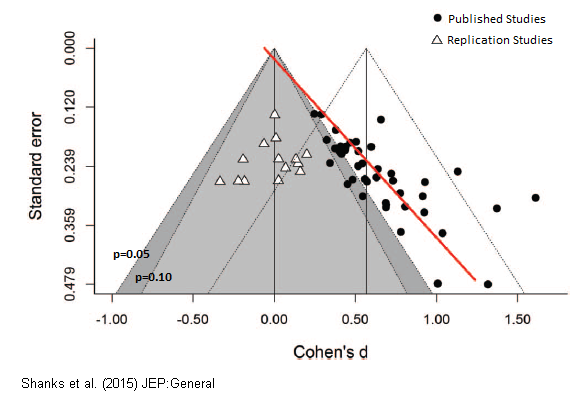
Sound similar to UXR?
- "Prove me right"
- Demanding shortcuts
- Preferring 'hard data' over qual data

Science
Chipping away at the crystal of knowledge

UXR
Reducing business risk
So does reproducibility even matter in UXR?
Well yes...
we are
Science lite
Said with ❤️
Debunked ideas
There's a good chance that a bunch of the scientific ideas you’ve learned are now outdated and debunked. Here are some of the ones I feel most strongly about 👇 (1/7)
— Dorsa Amir (@DorsaAmir) March 26, 2019
Are you an ENTP or an ISTJ? Turns out it doesn’t matter ¯\_(ツ)_/¯ The Myers-Briggs personality questionnaire has pretty poor validity & reliability. It's basically astrology. FYI, the "Big Five" is a way better personality framework. (2/7) https://t.co/3bFXN1eVpC pic.twitter.com/7tfQrYxUb7
— Dorsa Amir (@DorsaAmir) March 26, 2019
Method/problem mismatches
Make the hard problem of internal buy-in harder
"But we did 'User Testing'"
— Cameron Rogers (@cameron_rogers) March 28, 2019
Why testing prototypes won't validate your product ideas.https://t.co/AIeSNdRWfs
It is entirely possible to do a tonne of research and keep heading in the wrong direction. It is not about volume or speed of research, it is about making sure you're looking for the right things in the right places. Please use great caution if your purpose is validation.
— Leisa Reichelt (@leisa) March 27, 2019
A lot of UX #research looks to me like: “Well we gave users two hammers and lo and behold, they pounded nails, but they pounded nails differently.”
— Ha Phan (@hpdailyrant) April 2, 2019
It doesn't matter how much research you do if you haven't laid the foundation for evidence-based decision-making in advance.
— Erika Hall (@mulegirl) March 27, 2019
Plenty of organizations pay for research, ignore it, and use that as the reason why research is a waste of resources.
So, should UX Research be reproducible?
My answer is...
Sometimes!*
*It depends
1. Experiment design
- Model & Methodology
- Sample size
- Sample selection
2. Data captured
3. Interpretation
UX Research types
Qualitative -vs- Quantitative
Qualitative
- Experiment design ✔
- Data captured ×
- Interpretation ×
Quantitative
- Experiment design ✔
- Data captured ✔
- Interpretation ✔
- Hopefully 🤞
How do we do it better?
Get inspired by the Open Science movement
Within the constraints of our current workplaces...
Crunching numbers
So you want statistical significance
- Work on your research design hygiene
- Get better at understanding the strength of your signal
Embrace uncertainty
Like a scientist
- Avoid speaking in absolutes
- Cultivate your curiousity
- Reward "I don't know"

Define your study
before
you start
Plan for no conclusion
(unclear results)
Replication studies
Start by identifying a good candidate study
Good
- expect the effect to be consistent over time
- the hypothesis is important to business model functioning
- product has been consistent since last study
Poor
- don't expect the effect to be consistent
- low risk to business model or low business priority
- UX or UI in flux; too many variables to control for
Qual data
Consider trying synthesis and interpretation with multiple groups of researchers
Fact check
- Learn to read references
- Paper abstract is a good start
- Develop your sniff test
Open UX...?
Continuous discovery...?
Recommendations
- Build culture for continuous learning
- Embrace uncertainty
- Replication studies (maybe)
- Spend more time on research design & analysis
- Uncertain results are ok
"In short, be sceptical, pick a good question, and try to answer it in many ways. It takes many numbers to get close to the truth."
Thanks!
Get the slides
summerscope.github.io/slides/art-vs-science
Power Pose
- fortune.com/2016/10/02/power-poses-research-false/
- time.com/4949675/power-poses-confidence/
- nytimes.com/2017/10/18/magazine/when-the-revolution-came-for-amy-cuddy.html
- sciencedaily.com/releases/2017/09/170911095932.htm
- https://journals.sagepub.com/doi/full/10.1177/0956797614553946
- forbes.com/sites/kimelsesser/2018/04/03/power-posing-is-back-amy-cuddy-successfully-refutes-criticism/#3c9a913c3b8e
A/B Tools
Further reading
- Scientific Studies: Last Week Tonight with John Oliver
- Wikipedia - Reproducibility Project
- Wikipedia - Null Result
- A replication tour de force
- Five Thirty-eight
- Why most published research findings are false
- John Arnold waging war on bad science
- "Cargo Cult Science" by Richard Feynman
- The 9 Rules of Design Research
- ML contributing to a reproducibility crisis within science
- The secret cost of research
- More social science studies just failed to replicate
- Center for Open Science
- Open Science Foundation